Video Overview
Self-Play for End-to-End Driving
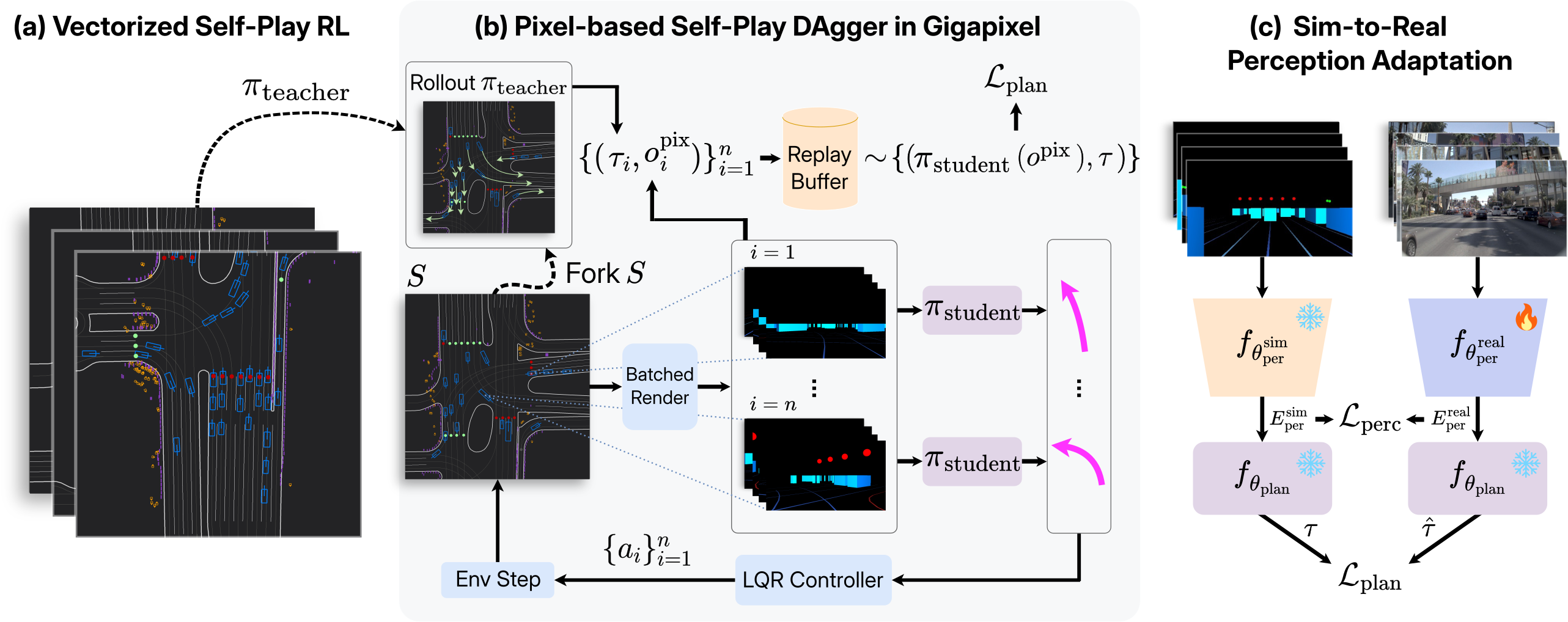
The Gigapixel Renderer
Gigapixel extends the PufferDrive batched simulator with the GPU-accelerated Madrona renderer, exposing ego-centric perspective views rather than only vectorized BEV features. It renders a deliberately simple bounding-box world (vehicles and static objects as cuboids, lane polylines as thin planar strips, and traffic lights as small spheres) preserving the scene geometry and interaction fidelity needed for planning while sustaining 50k agent steps per second on a single GPU, scaling near-linearly with the number of GPUs.
Gigapixel Rollouts
The ego-centric pixel observations a policy receives during self-play, stitched across the forward camera views. Blue cuboids are surrounding agents, thin strips are lane polylines, and the small colored spheres are traffic lights.

Two Rendering Backends
Gigapixel supports rasterized and ray-traced rendering. The rasterizer is faster, exploiting the simplicity of the primitives; the ray tracer trades throughput for higher visual fidelity, which is visible in the richer shading of the lower rows.
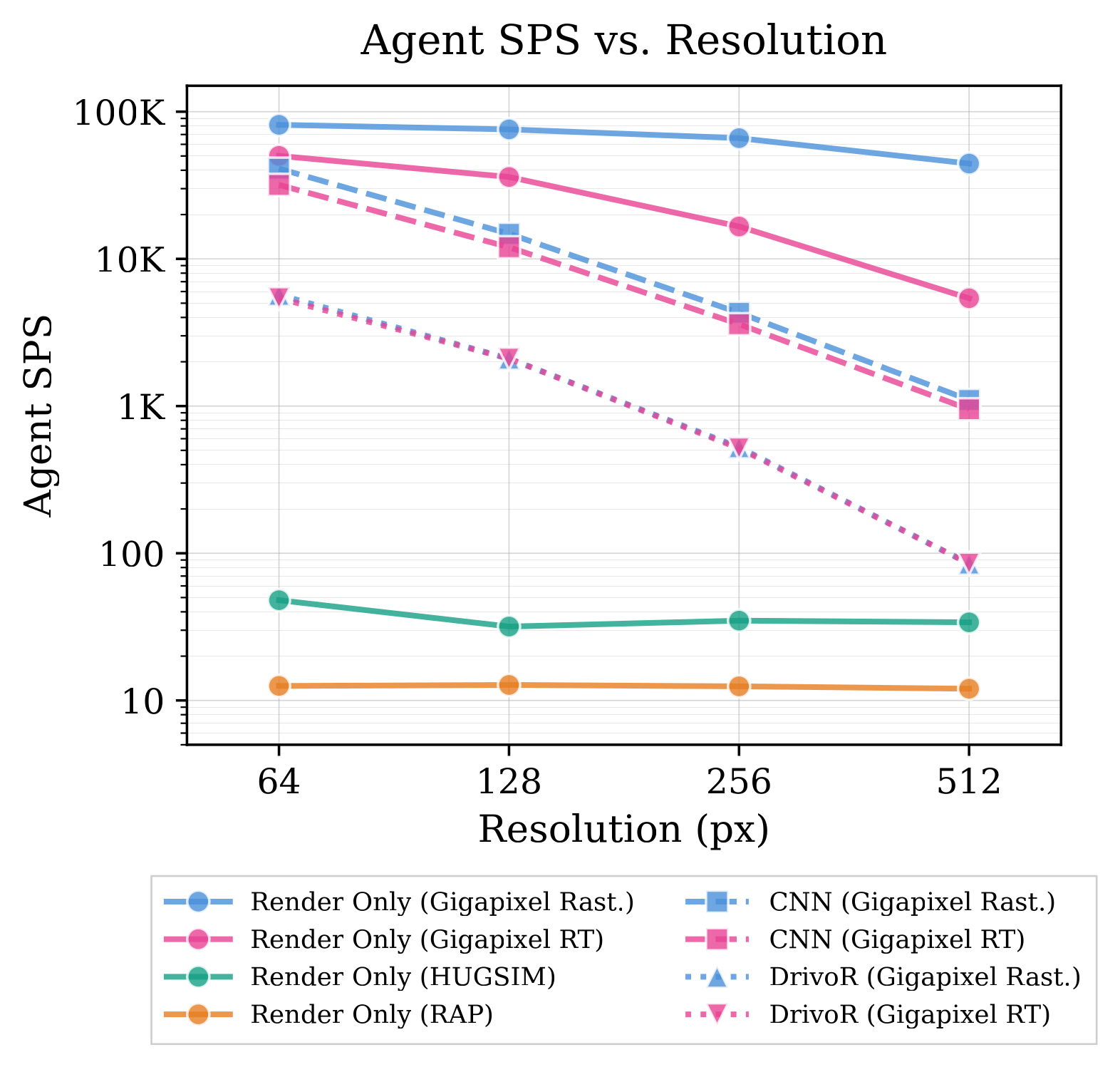
Throughput vs. Resolution
Agent steps per second (SPS) across rendering resolutions and policy architectures on one NVIDIA A100 GPU. Render Only isolates renderer throughput, with no policy forward or backward pass.
- The Gigapixel rasterizer is ~1000× faster than the Gaussian-splatting HUGSIM renderer and ~4000× faster than the CPU rasterizer RAP at 512×512.
- The gap between the rasterizer (Rast.) and ray tracer (RT) narrows as model complexity grows (CNN → DrivoR). This confirms that with a heavy end-to-end model, the renderer is no longer the throughput bottleneck.
Self-Play vs. Behavior Cloning
We compare two pixel-based DrivoR policies driving closed-loop in photorealistic reconstructed real-world scenes. Both share the same architecture; only the training signal differs.
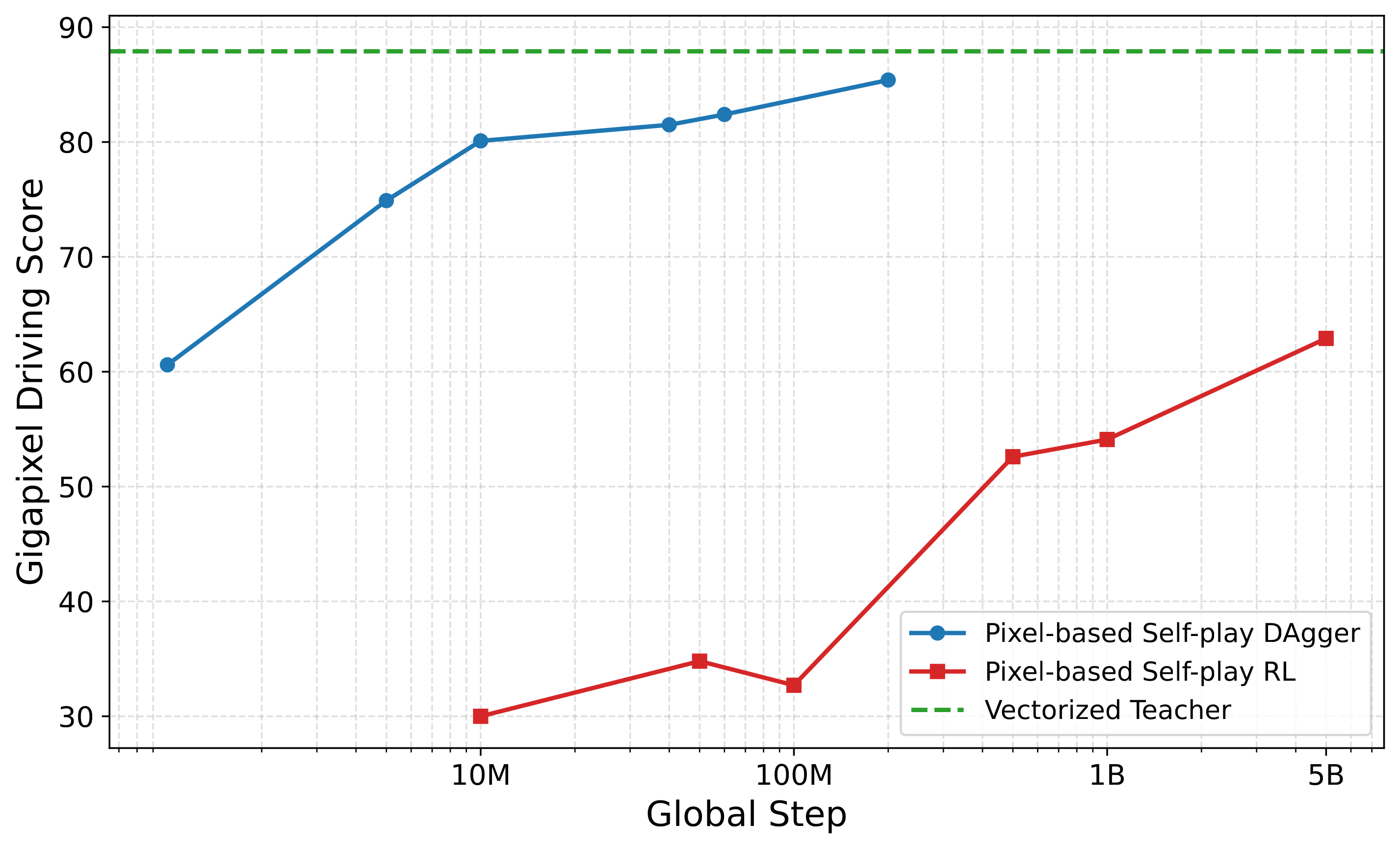
Self-Play DAgger is More Sample-Efficient than Self-Play RL
Using a lightweight CNN policy (for tractable RL experimentation), we compare distilling a privileged teacher via self-play DAgger against training the pixel policy directly with self-play RL.
- Self-play DAgger surpasses a Gigapixel Driving Score of 60 in roughly 3000× fewer steps than self-play RL.
- It quickly approaches the vectorized teacher's performance (dashed line, reached at 25B steps).
- This motivates distilling an RL teacher rather than training a large pixel policy with RL from scratch.
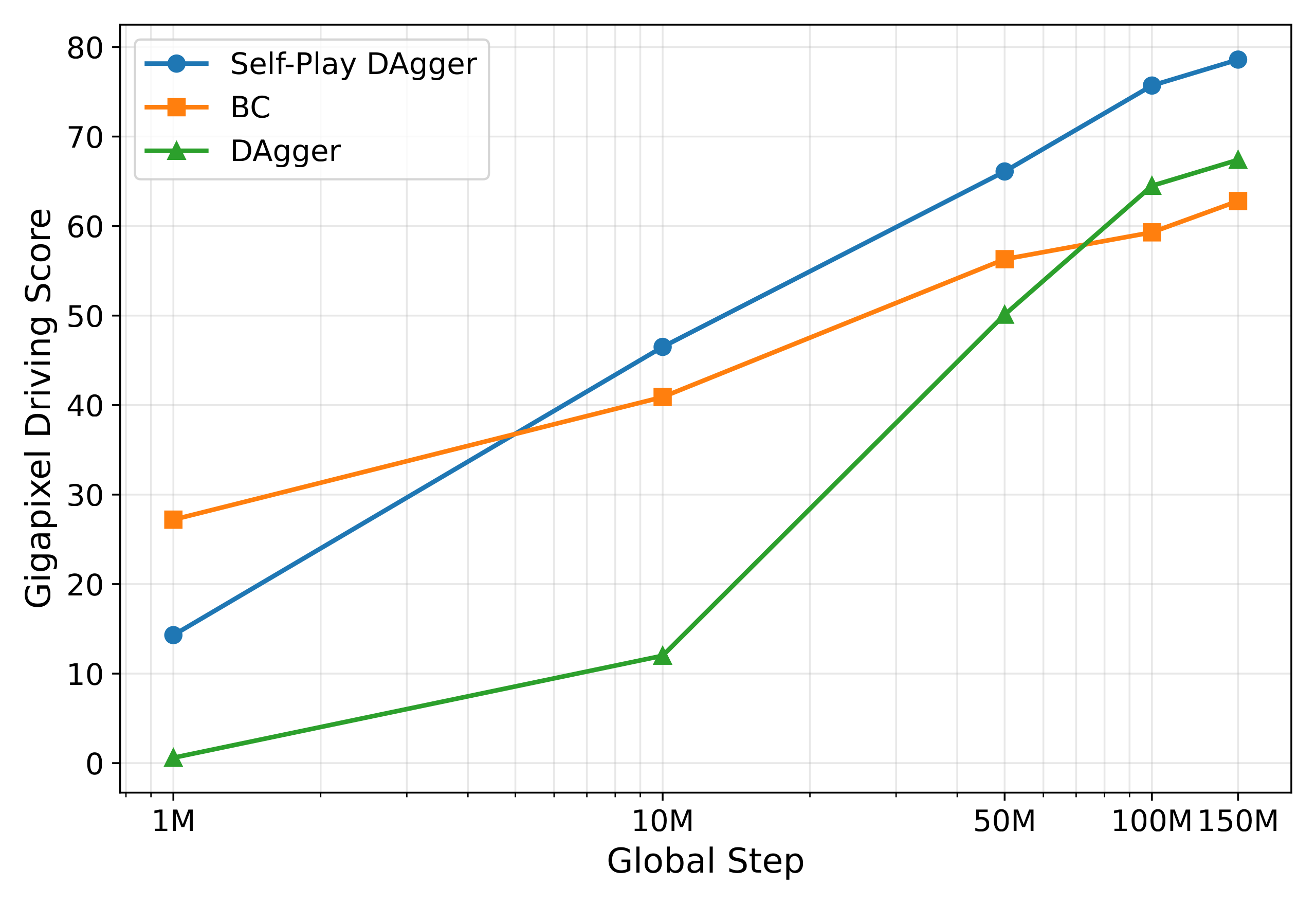
Scaling Self-Play
Closed-loop performance of the DrivoR-Reg student as training experience scales in Gigapixel, across three end-to-end training strategies.
- Self-play DAgger improves consistently with scale and overtakes both single-agent DAgger and behavior cloning beyond 10M steps.
- Behavior cloning plateaus around 100M steps, as the student is never exposed to consequences of its own actions.
- Self-play's edge comes from two effects: every agent in a rollout contributes supervised data, and the co-evolving interactions span more diverse, safety-critical states.
BibTeX
If you find this work useful, please consider citing it.
@article{rowe2026gigapixel,
title = {Scaling Self-Play for End-to-End Driving},
author = {Rowe, Luke and Girgis, Roger and de Schaetzen, Rodrigue and
Cornelisse, Daphne and Grandhi, Alaap and Heide, Felix and
Vinitsky, Eugene and Pal, Christopher and Paull, Liam},
journal = {arXiv preprint arXiv:2606.19641},
year = {2026}
}