
One-4-all: Neural potential fields for embodied navigation Sacha Morin, Miguel Saavedra-Ruiz, and Liam Paull In 2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) 2023 Abstract arXiv Project Page Video BibTeX A fundamental task in robotics is to navigate between two locations. In particular, real-world navigation can require long-horizon planning using high-dimensional RGB images, which poses a substantial challenge for end-to-end learning-based approaches. Current semi-parametric methods instead achieve long-horizon navigation by combining learned modules with a topological memory of the environment, often represented as a graph over previously collected images. However, using these graphs in practice requires tuning a number of pruning heuristics. These heuristics are necessary to avoid spurious edges, limit runtime memory usage and maintain reasonably fast graph queries in large environments. In this work, we present One-4-All (O4A), a method leveraging self-supervised and manifold learning to obtain a graph-free, end-to-end navigation pipeline in which the goal is specified as an image. Navigation is achieved by greedily minimizing a potential function defined continuously over image embeddings. Our system is trained offline on non-expert exploration sequences of RGB data and controls, and does not require any depth or pose measurements. We show that O4A can reach long-range goals in 8 simulated Gibson indoor environments and that resulting embeddings are topologically similar to ground truth maps, even if no pose is observed. We further demonstrate successful real-world navigation using a Jackal UGV platform.
@inproceedings{ morin2023one,
author = { Morin, Sacha and Saavedra-Ruiz, Miguel and Paull, Liam },
title = { One-4-all: Neural potential fields for embodied navigation },
booktitle = { 2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) },
year = { 2023 },
}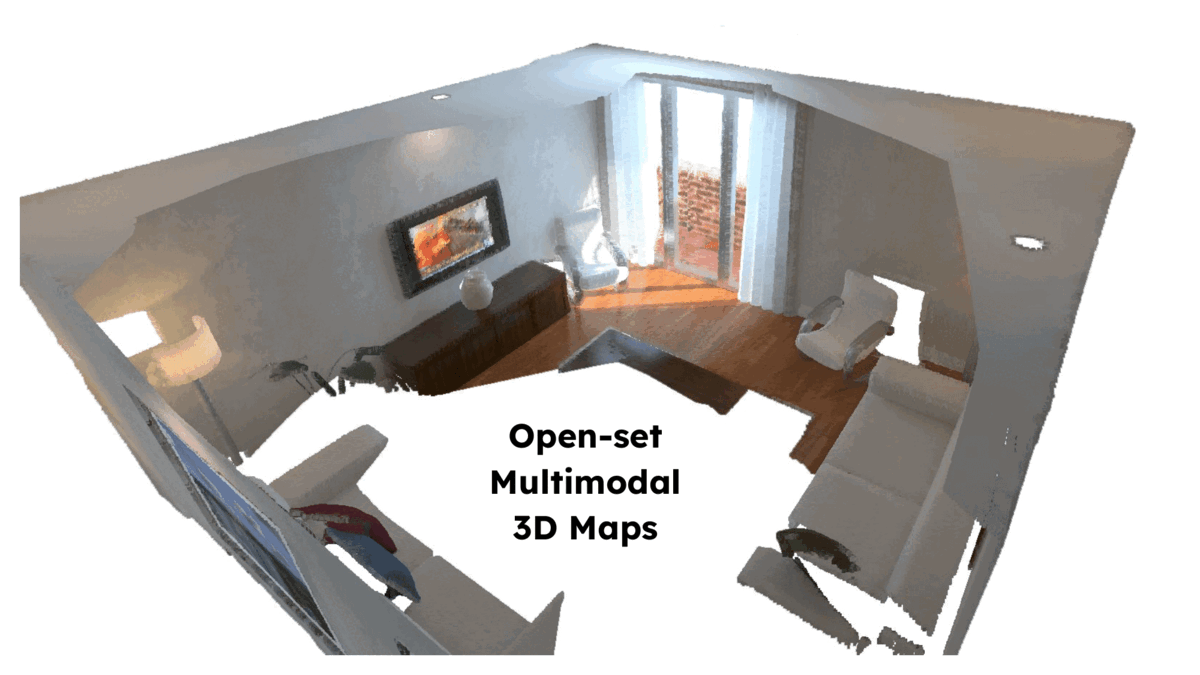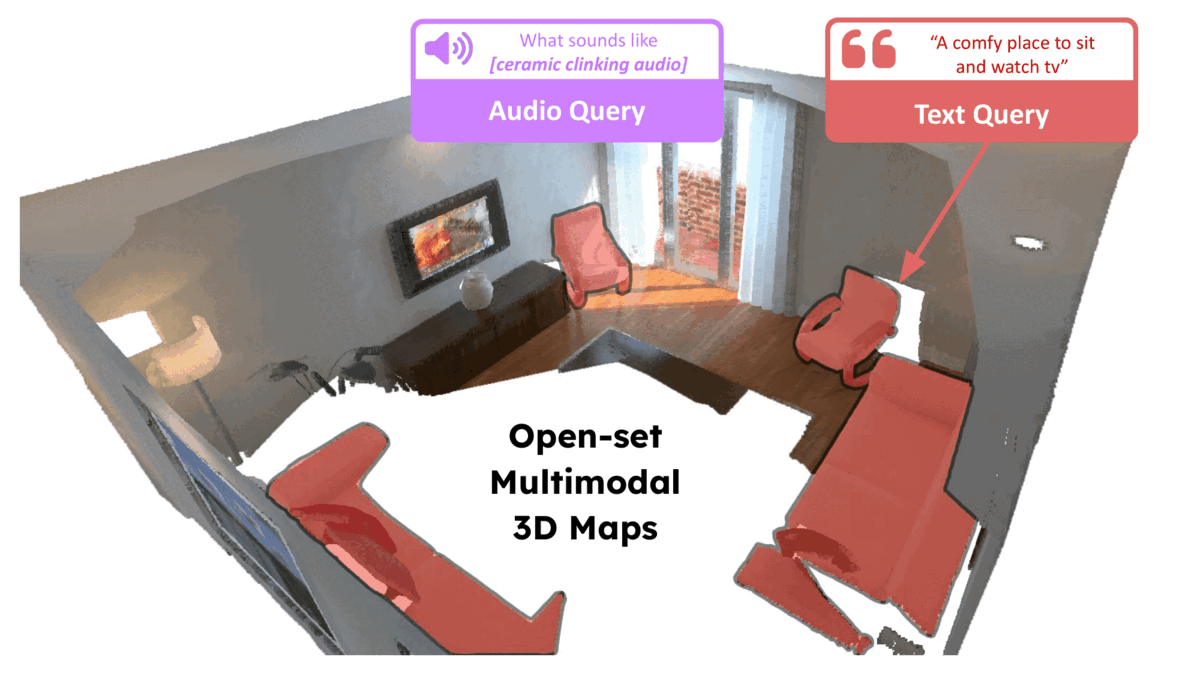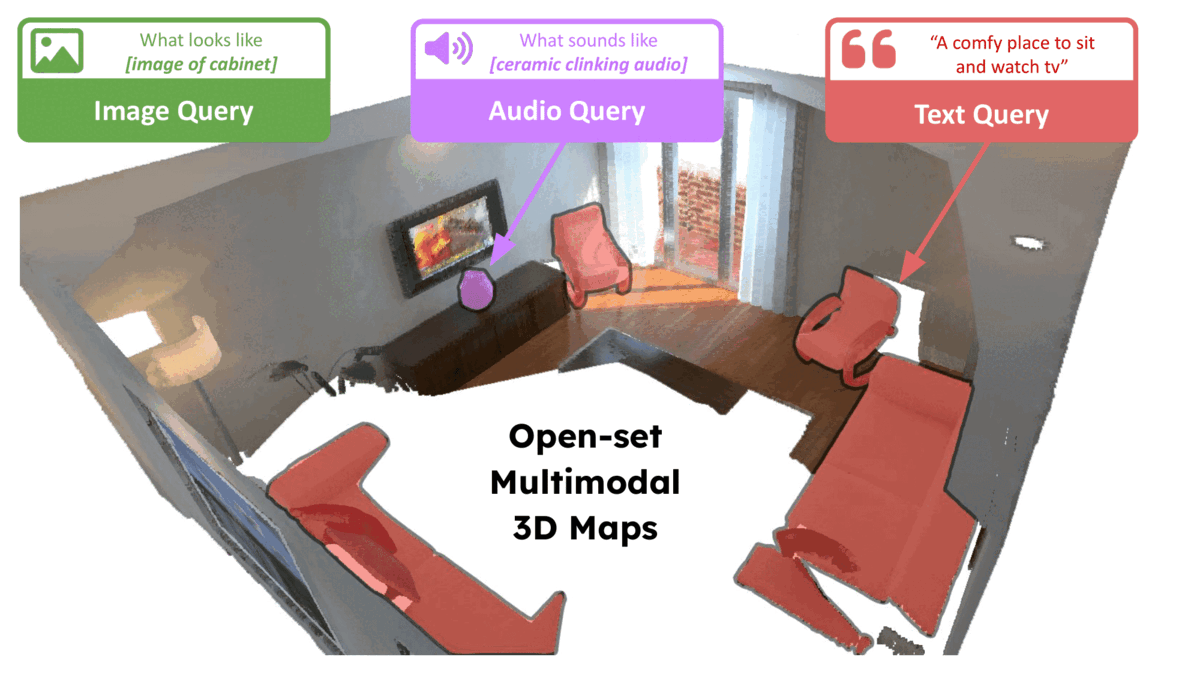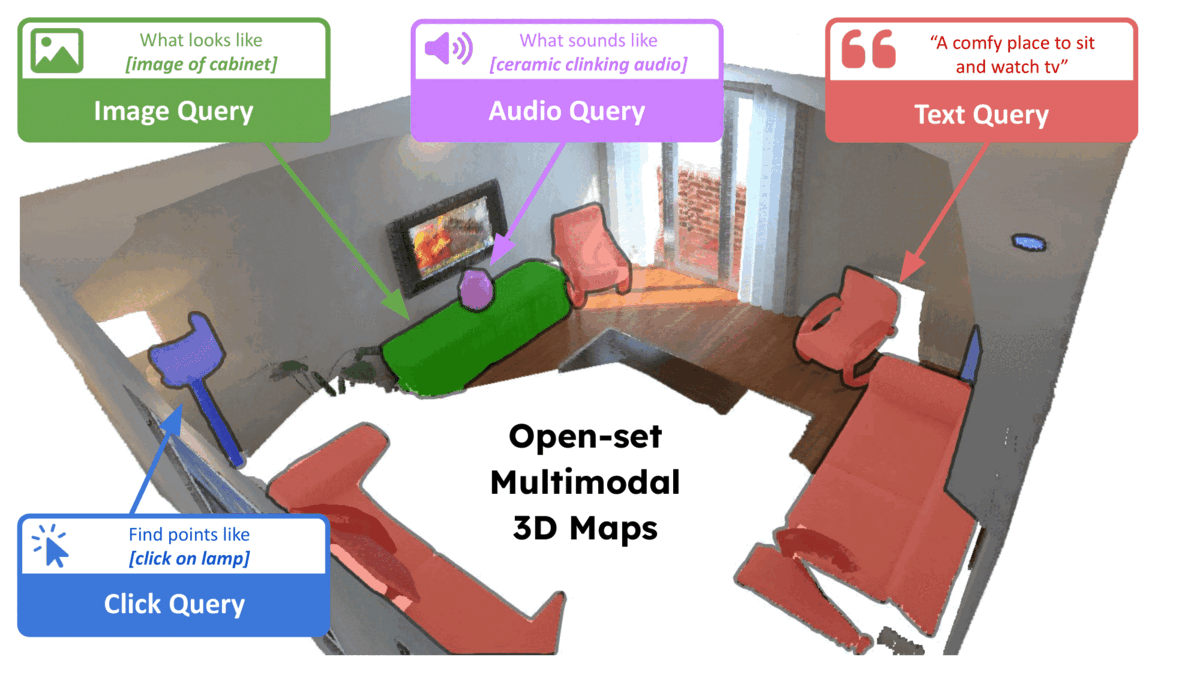
ConceptFusion: Open-set Multimodal 3D Mapping Krishna Murthy Jatavallabhula, Alihusein Kuwajerwala, Qiao Gu, Mohd Omama, Tao Chen, Shuang Li, Ganesh Iyer, Soroush Saryazdi, Nikhil Keetha, Ayush Tewari, Joshua B. Tenenbaum, Celso Miguel de Melo, Madhava Krishna, Liam Paull, Florian Shkurti, and Antonio Torralba Robotics: Science and Systems (RSS) 2023 Abstract arXiv Project Page Video BibTeX Building 3D maps of the environment is central to robot navigation, planning, and interaction with objects in a scene. Most existing approaches that integrate semantic concepts with 3D maps largely remain confined to the closed-set setting: they can only reason about a finite set of concepts, pre-defined at training time. Further, these maps can only be queried using class labels, or in recent work, using text prompts. We address both these issues with ConceptFusion, a scene representation that is (1) fundamentally open-set, enabling reasoning beyond a closed set of concepts and (ii) inherently multimodal, enabling a diverse range of possible queries to the 3D map, from language, to images, to audio, to 3D geometry, all working in concert. ConceptFusion leverages the open-set capabilities of today’s foundation models pre-trained on internet-scale data to reason about concepts across modalities such as natural language, images, and audio. We demonstrate that pixel-aligned open-set features can be fused into 3D maps via traditional SLAM and multi-view fusion approaches. This enables effective zero-shot spatial reasoning, not needing any additional training or finetuning, and retains long-tailed concepts better than supervised approaches, outperforming them by more than 40 percent margin on 3D IoU. We extensively evaluate ConceptFusion on a number of real-world datasets, simulated home environments, a real-world tabletop manipulation task, and an autonomous driving platform. We showcase new avenues for blending foundation models with 3D open-set multimodal mapping.
@inproceedings{ conceptfusion,
author = { Jatavallabhula, Krishna Murthy and Kuwajerwala, Alihusein and Gu, Qiao and Omama, Mohd and Chen, Tao and Li, Shuang and Iyer, Ganesh and Saryazdi, Soroush and Keetha, Nikhil and Tewari, Ayush and Tenenbaum, Joshua B. and de Melo, Celso Miguel and Krishna, Madhava and Paull, Liam and Shkurti, Florian and Torralba, Antonio },
title = { ConceptFusion: Open-set Multimodal 3D Mapping },
journal = { Robotics: Science and Systems (RSS) },
year = { 2023 },
}
MeshDiffusion: Score-based Generative 3D Mesh Modeling Zhen Liu, Yao Feng, Michael J Black, Derek Nowrouzezahrai, Liam Paull, and Weiyang Liu In The Eleventh International Conference on Learning Representations 2023 Abstract arXiv Project Page BibTeX We consider the task of generating realistic 3D shapes, which is useful for a variety of applications such as automatic scene generation and physical simulation. Compared to other 3D representations like voxels and point clouds, meshes are more desirable in practice, because (1) they enable easy and arbitrary manipulation of shapes for relighting and simulation, and (2) they can fully leverage the power of modern graphics pipelines which are mostly optimized for meshes. Previous scalable methods for generating meshes typically rely on sub-optimal post-processing, and they tend to produce overly-smooth or noisy surfaces without fine-grained geometric details. To overcome these shortcomings, we take advantage of the graph structure of meshes and use a simple yet very effective generative modeling method to generate 3D meshes. Specifically, we represent meshes with deformable tetrahedral grids, and then train a diffusion model on this direct parametrization. We demonstrate the effectiveness of our model on multiple generative tasks.
@inproceedings{ liu2023meshdiffusion,
author = { Liu, Zhen and Feng, Yao and Black, Michael J and Nowrouzezahrai, Derek and Paull, Liam and Liu, Weiyang },
title = { MeshDiffusion: Score-based Generative 3D Mesh Modeling },
booktitle = { The Eleventh International Conference on Learning Representations },
year = { 2023 },
}

Hierarchical Reinforcement Learning for Precise Soccer Shooting Skills using a Quadrupedal Robot Yandong Ji, Zhongyu Li*, Yinan Sun, Xue Bin Peng, Sergey Levine, Glen Berseth, and Koushil Sreenath In Proc. IEEE/RSJ Intl Conf on Intelligent Robots and Systems (IROS 2022) 2022 Abstract arXiv Project Page Video BibTeX We address the problem of enabling quadrupedal robots to perform precise shooting skills in the real world using reinforcement learning. Developing algorithms to enable a legged robot to shoot a soccer ball to a given target is a challenging problem that combines robot motion control and planning into one task. To solve this problem, we need to consider the dynamics limitation and motion stability during the control of a dynamic legged robot. Moreover, we need to consider motion planning to shoot the hard-to-model deformable ball rolling on the ground with uncertain friction to a desired location. In this paper, we propose a hierarchical framework that leverages deep reinforcement learning to train (a) a robust motion control policy that can track arbitrary motions and (b) a planning policy to decide the desired kicking motion to shoot a soccer ball to a target. We deploy the proposed framework on an A1 quadrupedal robot and enable it to accurately shoot the ball to random targets in the real world.
@inproceedings{ quadsoccer,
author = { Ji, Yandong and Li*, Zhongyu and Sun, Yinan and Peng, Xue Bin and Levine, Sergey and Berseth, Glen and Sreenath, Koushil },
title = { Hierarchical Reinforcement Learning for Precise Soccer Shooting Skills using a Quadrupedal Robot },
booktitle = { Proc. IEEE/RSJ Intl Conf on Intelligent Robots and Systems (IROS 2022) },
year = { 2022 },
}
AnyMorph: Learning Transferable Policies By Inferring Agent Morphology Brandon Trabucco, Phielipp Mariano, and Glen Berseth Internation Conference on Machine Learning 2022 Abstract arXiv Project Page BibTeX The prototypical approach to reinforcement learning involves training policies tailored to a particular agent from scratch for every new morphology. Recent work aims to eliminate the re-training of policies by investigating whether a morphology-agnostic policy, trained on a diverse set of agents with similar task objectives, can be transferred to new agents with unseen morphologies without re-training. This is a challenging problem that required previous approaches to use hand-designed descriptions of the new agent’s morphology. Instead of hand-designing this description, we propose a data-driven method that learns a representation of morphology directly from the reinforcement learning objective. Ours is the first reinforcement learning algorithm that can train a policy to generalize to new agent morphologies without requiring a description of the agent’s morphology in advance. We evaluate our approach on the standard benchmark for agent-agnostic control, and improve over the current state of the art in zero-shot generalization to new agents. Importantly, our method attains good performance without an explicit description of morphology.
@inproceedings{ Traboco2022,
author = { Trabucco, Brandon and Mariano, Phielipp and Berseth, Glen },
title = { AnyMorph: Learning Transferable Policies By Inferring Agent Morphology },
journal = { Internation Conference on Machine Learning },
year = { 2022 },
}
Lifelong Topological Visual Navigation Rey Reza Wiyatno, Anqi Xu, and Liam Paull IEEE Robotics and Automation Letters 2022 Abstract arXiv Project Page BibTeX Commonly, learning-based topological navigation approaches produce a local policy while preserving some loose connectivity of the space through a topological map. Nevertheless, spurious or missing edges in the topological graph often lead to navigation failure. In this work, we propose a sampling-based graph building method, which results in sparser graphs yet with higher navigation performance compared to baseline methods. We also propose graph maintenance strategies that eliminate spurious edges and expand the graph as needed, which improves lifelong navigation performance. Unlike controllers that learn from fixed training environments, we show that our model can be fine-tuned using only a small number of collected trajectory images from a real-world environment where the agent is deployed. We demonstrate successful navigation after fine-tuning on real-world environments, and notably show significant navigation improvements over time by applying our lifelong graph maintenance strategies.
@inproceedings{ wiyatno2022lifelong,
author = { Wiyatno, Rey Reza and Xu, Anqi and Paull, Liam },
title = { Lifelong Topological Visual Navigation },
journal = { IEEE Robotics and Automation Letters },
year = { 2022 },
}
Sample efficient deep reinforcement learning via uncertainty estimation Vincent Mai, Kaustubh Mani, and Liam Paull International Conference on Learning Representations (ICLR) 2022 Abstract arXiv BibTeX In model-free deep reinforcement learning (RL) algorithms, using noisy value estimates to supervise policy evaluation and optimization is detrimental to the sample efficiency. As this noise is heteroscedastic, its effects can be mitigated using uncertainty-based weights in the optimization process. Previous methods rely on sampled ensembles, which do not capture all aspects of uncertainty. We provide a systematic analysis of the sources of uncertainty in the noisy supervision that occurs in RL, and introduce inverse-variance RL, a Bayesian framework which combines probabilistic ensembles and Batch Inverse Variance weighting. We propose a method whereby two complementary uncertainty estimation methods account for both the Q-value and the environment stochasticity to better mitigate the negative impacts of noisy supervision. Our results show significant improvement in terms of sample efficiency on discrete and continuous control tasks.
@inproceedings{ mai2022sample,
author = { Mai, Vincent and Mani, Kaustubh and Paull, Liam },
title = { Sample efficient deep reinforcement learning via uncertainty estimation },
journal = { International Conference on Learning Representations (ICLR) },
year = { 2022 },
}
Monocular Robot Navigation with Self-Supervised Pretrained Vision Transformers Miguel Saavedra-Ruiz, Sacha Morin, and Liam Paull In 2022 Abstract arXiv BibTeX In this work, we consider the problem of learning a perception model for monocular robot navigation using few annotated images. Using a Vision Transformer (ViT) pretrained with a label-free self-supervised method, we successfully train a coarse image segmentation model for the Duckietown environment using 70 training images. Our model performs coarse image segmentation at the 8x8 patch level, and the inference resolution can be adjusted to balance prediction granularity and real-time perception constraints. We study how best to adapt a ViT to our task and environment, and find that some lightweight architectures can yield good single-image segmentation at a usable frame rate, even on CPU. The resulting perception model is used as the backbone for a simple yet robust visual servoing agent, which we deploy on a differential drive mobile robot to perform two tasks: lane following and obstacle avoidance.
@inproceedings{ saavedra2022monocular,
author = { Saavedra-Ruiz, Miguel and Morin, Sacha and Paull, Liam },
title = { Monocular Robot Navigation with Self-Supervised Pretrained Vision Transformers },
journal = { IEEE Conference on Robots and Vision },
year = { 2022 },
}
Generalization Games for Reinforcement Learning Manfred Diaz, Charlie Gauthier, Glen Berseth, and Liam Paull In ICLR 2022 Workshop on Gamification and Multiagent Solutions 2022 Abstract OpenReview BibTeX In reinforcement learning (RL), the term generalization has either denoted introducing function approximation to reduce the intractability of problems with large state and action spaces or designated RL agents’ ability to transfer learned experiences to one or more evaluation tasks. Recently, many subfields have emerged to understand how distributions of training tasks affect an RL agent’s performance in unseen environments. While the field is extensive and ever-growing, recent research has underlined that variability among the different approaches is not as significant. We leverage this intuition to demonstrate how current methods for generalization in RL are specializations of a general framework. We obtain the fundamental aspects of this formulation by rebuilding a Markov Decision Process (MDP) from the ground up by resurfacing the game-theoretic framework of games against nature. The two-player game that arises from considering nature as a complete player in this formulation explains how existing methods rely on learned and randomized dynamics and initial state distributions. We develop this result further by drawing inspiration from mechanism design theory to introduce the role of a principal as a third player that can modify the payoff functions of the decision-making agent and nature. The games induced by playing against the principal extend our framework to explain how learned and randomized reward functions induce generalization in RL agents. The main contribution of our work is the complete description of the Generalization Games for Reinforcement Learning, a multiagent, multiplayer, game-theoretic formal approach to study generalization methods in RL. We offer a preliminary ablation experiment of the different components of the framework. We demonstrate that a more simplified composition of the objectives that we introduce for each player leads to comparable, and in some cases superior, zero-shot generalization compared to state-of-the-art methods, all while requiring almost two orders of magnitude fewer samples.
@inproceedings{ diaz2022generalization,
author = { Diaz, Manfred and Gauthier, Charlie and Berseth, Glen and Paull, Liam },
title = { Generalization Games for Reinforcement Learning },
booktitle = { ICLR 2022 Workshop on Gamification and Multiagent Solutions },
year = { 2022 },
}
f-Cal: Aleatoric uncertainty quantification for robot perception via calibrated neural regression Dhaivat Bhatt, Kaustubh Mani, Dishank Bansal, Krishna Murthy, Hanju Lee, and Liam Paull In 2022 International Conference on Robotics and Automation (ICRA) 2022 Abstract PDF Project Page BibTeX While modern deep neural networks are performant perception modules, performance (accuracy) alone is insufficient, particularly for safety-critical robotic applications such as self-driving vehicles. Robot autonomy stacks also require these otherwise blackbox models to produce reliable and calibrated measures of confidence on their predictions. Existing approaches estimate uncertainty from these neural network perception stacks by modifying network architectures, inference procedure, or loss functions. However, in general, these methods lack calibration, meaning that the predictive uncertainties do not faithfully represent the true underlying uncertainties (process noise). Our key insight is that calibration is only achieved by imposing constraints across multiple examples, such as those in a mini-batch; as opposed to existing approaches which only impose constraints per-sample, often leading to overconfident (thus miscalibrated) uncertainty estimates. By enforcing the distribution of outputs of a neural network to resemble a target distribution by minimizing an f -divergence, we obtain significantly better-calibrated models compared to prior approaches. Our approach, f-Cal, outperforms existing uncertainty calibration approaches on robot perception tasks such as object detection and monocular depth estimation over multiple real-world benchmarks.
@inproceedings{ bhatt2022f,
author = { Bhatt, Dhaivat and Mani, Kaustubh and Bansal, Dishank and Murthy, Krishna and Lee, Hanju and Paull, Liam },
title = { f-Cal: Aleatoric uncertainty quantification for robot perception via calibrated neural regression },
booktitle = { 2022 International Conference on Robotics and Automation (ICRA) },
year = { 2022 },
}

Batch Inverse-Variance Weighting: Deep Heteroscedastic Regression Vincent Mai, Waleed Khamies, and Liam Paull In ICML Workshop on Uncertainty & Robustness in Deep Learning 2021 Abstract arXiv BibTeX In the supervised learning task of heteroscedastic regression, each label is subject to noise from a different distribution. The label generator may estimate the variance of the noise distribution for each label, which is useful information to mitigate its impact. We adapt an inverse-variance weighted mean square error, based on the Gauss-Markov theorem, for gradient descent on neural networks. We introduce Batch Inverse-Variance, a loss function which is robust to near-ground truth samples, and allows to control the effective learning rate. Our experimental results show that BIV improves significantly the performance of the networks on two noisy datasets, compared to L2 loss, inverse-variance weighting, and a filtering-based baseline.
@inproceedings{ biv,
author = { Mai, Vincent and Khamies, Waleed and Paull, Liam },
title = { Batch Inverse-Variance Weighting: Deep Heteroscedastic Regression },
booktitle = { ICML Workshop on Uncertainty & Robustness in Deep Learning },
year = { 2021 },
}
LOCO: Adaptive exploration in reinforcement learning via local estimation of contraction coefficients and Pablo Samuel Castro Manfred Diaz In Self-Supervision for Reinforcement Learning Workshop-ICLR 2021 2021 Abstract OpenReview PDF BibTeX We offer a novel approach to balance exploration and exploitation in reinforcement learning (RL). To do so, we characterize an environment’s exploration difficulty via the Second Largest Eigenvalue Modulus (SLEM) of the Markov chain induced by uniform stochastic behaviour. Specifically, we investigate the connection of state-space coverage with the SLEM of this Markov chain and use the theory of contraction coefficients to derive estimates of this eigenvalue of interest. Furthermore, we introduce a method for estimating the contraction coefficients on a local level and leverage it to design a novel exploration algorithm. We evaluate our algorithm on a series of GridWorld tasks of varying sizes and complexity.
@inproceedings{ loco,
author = { Manfred Diaz, Pablo Samuel Castro },
title = { LOCO: Adaptive exploration in reinforcement learning via local estimation of contraction coefficients },
booktitle = { Self-Supervision for Reinforcement Learning Workshop-ICLR 2021 },
year = { 2021 },
}
Orthogonal over-parameterized training Weiyang Liu, Rongmei Lin, Zhen Liu, James M Rehg, Liam Paull, Li Xiong, Le Song, and Adrian Weller In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2021 Abstract arXiv BibTeX The inductive bias of a neural network is largely determined by the architecture and the training algorithm. To achieve good generalization, how to effectively train a neural network is of great importance. We propose a novel orthogonal over-parameterized training (OPT) framework that can provably minimize the hyperspherical energy which characterizes the diversity of neurons on a hypersphere. By maintaining the minimum hyperspherical energy during training, OPT can greatly improve the empirical generalization. Specifically, OPT fixes the randomly initialized weights of the neurons and learns an orthogonal transformation that applies to these neurons. We consider multiple ways to learn such an orthogonal transformation, including unrolling orthogonalization algorithms, applying orthogonal parameterization, and designing orthogonality-preserving gradient descent. For better scalability, we propose the stochastic OPT which performs orthogonal transformation stochastically for partial dimensions of neurons. Interestingly, OPT reveals that learning a proper coordinate system for neurons is crucial to generalization. We provide some insights on why OPT yields better generalization. Extensive experiments validate the superiority of OPT over the standard training.
@inproceedings{ liu2021orthogonal,
author = { Liu, Weiyang and Lin, Rongmei and Liu, Zhen and Rehg, James M and Paull, Liam and Xiong, Li and Song, Le and Weller, Adrian },
title = { Orthogonal over-parameterized training },
booktitle = { Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition },
year = { 2021 },
}
Uncertainty-Aware Policy Sampling and Mixing for Safe Interactive Imitation Learning Manfred Diaz, Thomas Fevens, and Liam Paull In 2021 18th Conference on Robots and Vision (CRV) 2021 Abstract PDF BibTeX Teaching robots how to execute tasks through demonstrations is appealing since it sidesteps the need to explicitly specify a reward function. However, posing imitation learning as a simple supervised learning problem suffers from the well-known problem of distributional shift - the teacher will only demonstrate the optimal trajectory and therefore the learner is unable to recover if it deviates even slightly from this trajectory since it has no training data for this case. This problem has been overcome in the literature by some element of interactivity in the learning process - usually be somehow interleaving the execution of the learner and the teacher so that the teacher can demonstrate to the learner also how to recover from mistakes. In this paper, we consider the cases where the robot has the potential to do harm, and therefore safety must be imposed at every step in the learning process. We show that uncertainty is an appropriate measure of safety and that both the mixing of the policies and the data sampling procedure benefit from considering the uncertainty of both the learner and the teacher. Our method, uncertainty-aware policy sampling and mixing (UPMS), is used to teach an agent to drive down a lane with less safety violations and less queries to the teacher than state-of-the-art methods.
@inproceedings{ diaz2021uncertainty,
author = { Diaz, Manfred and Fevens, Thomas and Paull, Liam },
title = { Uncertainty-Aware Policy Sampling and Mixing for Safe Interactive Imitation Learning },
booktitle = { 2021 18th Conference on Robots and Vision (CRV) },
year = { 2021 },
}
Deep Koopman Representation for Control over Images (DKRCI) Philippe Laferrière, Samuel Laferrière, Steven Dahdah, James Richard Forbes, and Liam Paull In 2021 18th Conference on Robots and Vision (CRV) 2021 Abstract PDF BibTeX The Koopman operator provides a means to represent nonlinear systems as infinite dimensional linear systems in a lifted state space. This enables the application of linear control techniques to nonlinear systems. However, the choice of a finite number of lifting functions, or Koopman observables, is still an unresolved problem. Deep learning techniques have recently been used to jointly learn these lifting function along with the Koopman operator. However, these methods require knowledge of the system’s state space. In this paper, we present a method to learn a Koopman representation directly from images and control inputs. We then demonstrate our deep learning architecture on a cart-pole system with external inputs.
@inproceedings{ laferriere2021deep,
author = { Laferrière, Philippe and Laferrière, Samuel and Dahdah, Steven and Forbes, James Richard and Paull, Liam },
title = { Deep Koopman Representation for Control over Images (DKRCI) },
booktitle = { 2021 18th Conference on Robots and Vision (CRV) },
year = { 2021 },
}
Taskography: Evaluating robot task planning over large 3D scene graphs Christopher Agia, Krishna Murthy Jatavallabhula, Mohamed Khodeir, Ondrej Miksik, Vibhav Vineet, Mustafa Mukadam, Liam Paull, and Florian Shkurti In Conference on Robot Learning 2021 Abstract OpenReview PDF Project Page BibTeX 3D scene graphs (3DSGs) are an emerging description; unifying symbolic, topological, and metric scene representations. However, typical 3DSGs contain hundreds of objects and symbols even for small environments; rendering task planning on the full graph impractical. We construct TASKOGRAPHY, the first large-scale robotic task planning benchmark over 3DSGs. While most benchmarking efforts in this area focus on vision-based planning, we systematically study symbolic planning, to decouple planning performance from visual representation learning. We observe that, among existing methods, neither classical nor learning-based planners are capable of real-time planning over full 3DSGs. Enabling real-time planning demands progress on both (a) sparsifying 3DSGs for tractable planning and (b) designing planners that better exploit 3DSG hierarchies. Towards the former goal, we propose SCRUB, a task-conditioned 3DSG sparsification method; enabling classical planners to match and in some cases surpass state-of-the-art learning-based planners. Towards the latter goal, we propose SEEK, a procedure enabling learning-based planners to exploit 3DSG structure, reducing the number of replanning queries required by current best approaches by an order of magnitude. We will open-source all code and baselines to spur further research along the intersections of robot task planning, learning and 3DSGs.
@inproceedings{ agia2022taskography,
author = { Agia, Christopher and Jatavallabhula, Krishna Murthy and Khodeir, Mohamed and Miksik, Ondrej and Vineet, Vibhav and Mukadam, Mustafa and Paull, Liam and Shkurti, Florian },
title = { Taskography: Evaluating robot task planning over large 3D scene graphs },
booktitle = { Conference on Robot Learning },
year = { 2021 },
}
On Assessing the Usefulness of Proxy Domains for Developing and Evaluating Embodied Agents Anthony Courchesne, Andrea Censi, and Liam Paull In 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) 2021 Abstract arXiv BibTeX In many situations it is either impossible or impractical to develop and evaluate agents entirely on the target domain on which they will be deployed. This is particularly true in robotics, where doing experiments on hardware is much more arduous than in simulation. This has become arguably more so in the case of learning-based agents. To this end, considerable recent effort has been devoted to developing increasingly realistic and higher fidelity simulators. However, we lack any principled way to evaluate how good a “proxy domain” is, specifically in terms of how useful it is in helping us achieve our end objective of building an agent that performs well in the target domain. In this work, we investigate methods to address this need. We begin by clearly separating two uses of proxy domains that are often conflated: 1) their ability to be a faithful predictor of agent performance and 2) their ability to be a useful tool for learning. In this paper, we attempt to clarify the role of proxy domains and establish new proxy usefulness (PU) metrics to compare the usefulness of different proxy domains. We propose the relative predictive PU to assess the predictive ability of a proxy domain and the learning PU to quantify the usefulness of a proxy as a tool to generate learning data. Furthermore, we argue that the value of a proxy is conditioned on the task that it is being used to help solve. We demonstrate how these new metrics can be used to optimize parameters of the proxy domain for which obtaining ground truth via system identification is not trivial.
@inproceedings{ courchesne2021assessing,
author = { Courchesne, Anthony and Censi, Andrea and Paull, Liam },
title = { On Assessing the Usefulness of Proxy Domains for Developing and Evaluating Embodied Agents },
booktitle = { 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) },
year = { 2021 },
}
Iterative teaching by label synthesis Weiyang Liu, Zhen Liu, Hanchen Wang, Liam Paull, Bernhard Schölkopf, and Adrian Weller Advances in Neural Information Processing Systems (NeurIPS) 2021 Abstract OpenReview BibTeX In this paper, we consider the problem of iterative machine teaching, where a teacher provides examples sequentially based on the current iterative learner. In contrast to previous methods that have to scan over the entire pool and select teaching examples from it in each iteration, we propose a label synthesis teaching framework where the teacher randomly selects input teaching examples (e.g., images) and then synthesizes suitable outputs (e.g., labels) for them. We show that this framework can avoid costly example selection while still provably achieving exponential teachability. We propose multiple novel teaching algorithms in this framework. Finally, we empirically demonstrate the value of our framework.
@inproceedings{ liu2021iterative,
author = { Liu, Weiyang and Liu, Zhen and Wang, Hanchen and Paull, Liam and Schölkopf, Bernhard and Weller, Adrian },
title = { Iterative teaching by label synthesis },
journal = { Advances in Neural Information Processing Systems (NeurIPS) },
year = { 2021 },
}

gradSLAM: Dense SLAM meets automatic differentiation Jatavallabhula Krishna Murthy, Ganesh Iyer, and Liam Paull In International Conference on Robotics and Automation (ICRA) 2020 Abstract arXiv Project Page Code BibTeX The question of "representation" is central in the context of dense simultaneous localization and mapping (SLAM). Newer learning-based approaches have the potential to leverage data or task performance to directly inform the choice of representation. However, learning representations for SLAM has been an open question, because traditional SLAM systems are not end-to-end differentiable.In this work, we present gradSLAM, a differentiable computational graph take on SLAM. Leveraging the automatic differentiation capabilities of computational graphs, gradSLAM enables the design of SLAM systems that allow for gradient-based learning across each of their components, or the system as a whole. This is achieved by creating differentiable alternatives for each non-differentiable component in a typical dense SLAM system. Specifically, we demonstrate how to design differentiable trust-region optimizers, surface measurement and fusion schemes, as well as differentiate over rays, without sacrificing performance. This amalgamation of dense SLAM with computational graphs enables us to backprop all the way from 3D maps to 2D pixels, opening up new possibilities in gradient-based learning for SLAM.
@inproceedings{ gradslam,
author = { Krishna Murthy, Jatavallabhula and Iyer, Ganesh and Paull, Liam },
title = { gradSLAM: Dense SLAM meets automatic differentiation },
booktitle = { International Conference on Robotics and Automation (ICRA) },
year = { 2020 },
}
La-MAML: Look-ahead Meta Learning for Continual Learning Gunshi Gupta, Karmesh Yadav, and Liam Paull In Neural Information Processing Systems (Neurips) 2020 Oral (top 1.1%) Abstract arXiv Project Page BibTeX The continual learning problem involves training models with limited capacity to perform well on a set of an unknown number of sequentially arriving tasks. While meta-learning shows great potential for reducing interference between old and new tasks, the current training procedures tend to be either slow or offline, and sensitive to many hyper-parameters. In this work, we propose Look-ahead MAML (La-MAML), a fast optimisation-based meta-learning algorithm for online-continual learning, aided by a small episodic memory. Our proposed modulation of per-parameter learning rates in our meta-learning update allows us to draw connections to prior work on hypergradients and meta-descent. This provides a more flexible and efficient way to mitigate catastrophic forgetting compared to conventional prior-based methods. La-MAML achieves performance superior to other replay-based, prior-based and meta-learning based approaches for continual learning on real-world visual classification benchmarks.
@inproceedings{ lamaml,
author = { Gupta, Gunshi and Yadav, Karmesh and Paull, Liam },
title = { La-MAML: Look-ahead Meta Learning for Continual Learning },
booktitle = { Neural Information Processing Systems (Neurips) },
year = { 2020 },
}
Your GAN is Secretly an Energy-based Model and You Should Use Discriminator Driven Latent Sampling Tong Che, Ruixiang Zhang, Jascha Sohl-Dickstein, Hugo Larochelle, Liam Paull, Yuan Cao, and Yoshua Bengio In Neural Information Processing Systems (Neurips) 2020 Abstract arXiv BibTeX We show that the sum of the implicit generator log-density of a GAN with the logit score of the discriminator defines an energy function which yields the true data density when the generator is imperfect but the discriminator is optimal, thus making it possible to improve on the typical generator. To make that practical, we show that sampling from this modified density can be achieved by sampling in latent space according to an energy-based model induced by the sum of the latent prior log-density and the discriminator output score. This can be achieved by running a Langevin MCMC in latent space and then applying the generator function, which we call Discriminator Driven Latent Sampling (DDLS). We show that DDLS is highly efficient compared to previous methods which work in the high-dimensional pixel space and can be applied to improve on previously trained GANs of many types. We evaluate DDLS on both synthetic and real-world datasets qualitatively and quantitatively. On CIFAR-10, DDLS substantially improves the Inception Score of an off-the-shelf pre-trained SN-GAN from 8.22 to 9.09 which is even comparable to the class-conditional BigGAN model. This achieves a new state-of-the-art in unconditional image synthesis setting without introducing extra parameters or additional training.
@inproceedings{ che2020neurips,
author = { Che, Tong and Zhang, Ruixiang and Sohl-Dickstein, Jascha and Larochelle, Hugo and Paull, Liam and Cao, Yuan and Bengio, Yoshua },
title = { Your GAN is Secretly an Energy-based Model and You Should Use Discriminator Driven Latent Sampling },
booktitle = { Neural Information Processing Systems (Neurips) },
year = { 2020 },
}
Curriculum in Gradient-Based Meta-Reinforcement Learning Bhairav Mehta, Tristan Deleu, Sharath Chandra Raparthy, Christopher Pal, and Liam Paull In BETR-RL Workshop 2020 Abstract arXiv BibTeX Can Meta-RL use curriculum learning? In this work, we explore that question and find that curriculum learning stabilizes meta-RL in complex navigation and locomotion tasks. We also highlight issues with Meta-RL benchmarks by highlighting failure cases when we vary task distributions.
@inproceedings{ mehta2020curriculum,
author = { Mehta, Bhairav and Deleu, Tristan and Raparthy, Sharath Chandra and Pal, Christopher and Paull, Liam },
title = { Curriculum in Gradient-Based Meta-Reinforcement Learning },
booktitle = { BETR-RL Workshop },
year = { 2020 },
}
Generating Automatic Curricula via Self-Supervised Active Domain Randomization Sharath Chandra Raparthy, Bhairav Mehta, and Liam Paull In BETR-RL Workshop 2020 Abstract arXiv Code BibTeX Can you learn domain randomization curricula with no rewards? We show that agents trained via self-play in the ADR framework outperform uniform domain randomization by magnitudes in both simulated and real-world transfer.
@inproceedings{ ssadr,
author = { Raparthy, Sharath Chandra and Mehta, Bhairav and Paull, Liam },
title = { Generating Automatic Curricula via Self-Supervised Active Domain Randomization },
booktitle = { BETR-RL Workshop },
year = { 2020 },
}
The AI Driving Olympics at NeurIPS 2018 Julian Zilly, Jacopo Tani, Breandan Considine, Bhairav Mehta, Andrea F Daniele, Manfred Diaz, Gianmarco Bernasconi, Jan Ruch, Florian Golemo, A Kirsten Bowser, Matthew R Walter, Ruslan Hristov, Sunil Mallya, Emilio Frazzoli, Andrea Censi, and Liam Paull In Springer 2020 Abstract arXiv BibTeX Despite recent breakthroughs, the ability of deep learning and reinforcement learning to outperform traditional approaches to control physically embodied robotic agents remains largely unproven. To help bridge this gap, we created the “AI Driving Olympics” (AI-DO), a competition with the objective of evaluating the state of the art in machine learning and artificial intelligence for mobile robotics. Based on the simple and well specified autonomous driving and navigation environment called “Duckietown,” AI-DO includes a series of tasks of increasing complexity – from simple lane-following to fleet management. For each task, we provide tools for competitors to use in the form of simulators, logs, code templates, baseline implementations and low-cost access to robotic hardware. We evaluate submissions in simulation online, on standardized hardware environments, and finally at the competition event. The first AI-DO, AI-DO 1, occurred at the Neural Information Processing Systems (NeurIPS) conference in December 2018. The results of AI-DO 1 highlight the need for better benchmarks, which are lacking in robotics, as well as improved mechanisms to bridge the gap between simulation and reality.
@inproceedings{ aido2018,
author = { Zilly, Julian and Tani, Jacopo and Considine, Breandan and Mehta, Bhairav and Daniele, Andrea F and Diaz, Manfred and Bernasconi, Gianmarco and Ruch, Jan and Golemo, Florian and Bowser, A Kirsten and Walter, Matthew R and Hristov, Ruslan and Mallya, Sunil and Frazzoli, Emilio and Censi, Andrea and Paull, Liam },
title = { The AI Driving Olympics at NeurIPS 2018 },
booktitle = { Springer },
year = { 2020 },
}
Probabilistic Object Detection: Strenghts, Weaknesses, and Opportunities Dhaivat Bhatt, Dishank Bansal, Gunshi Gupta, Krishna Murthy Jatavallabhula, Hanju Lee, and Liam Paull In ICML workshop on AI for autonomous driving 2020 Abstract Project Page BibTeX Deep neural networks are the de-facto standard for object detection in autonomous driving applications. However, neural networks cannot be blindly trusted even within the training data distribution, let alone outside it. This has paved way for several probabilistic object detection techniques that measure uncertainty in the outputs of an object detector. Through this position paper, we serve three main purposes. First, we briefly sketch the landscape of current methods for probabilistic object detection. Second, we present the main shortcomings of these approaches. Finally, we present promising avenues for future research, and proof-of-concept results where applicable. Through this effort, we hope to bring the community one step closer to performing accurate, reliable, and consistent probabilistic object detection.
@inproceedings{ probod,
author = { Bhatt, Dhaivat and Bansal, Dishank and Gupta, Gunshi and Jatavallabhula, Krishna Murthy and Lee, Hanju and Paull, Liam },
title = { Probabilistic Object Detection: Strenghts, Weaknesses, and Opportunities },
booktitle = { ICML workshop on AI for autonomous driving },
year = { 2020 },
}
MapLite: Autonomous Intersection Navigation without a Detailed Prior Map Teddy Ort, Krishna Murthy, Rohan Banerjee, Sai Krishna Gottipati, Dhaivat Bhatt, Igor Gilitschenski, Liam Paull, and Daniela Rus IEEE Robotics and Automation Letters 2020 Abstract PDF BibTeX In this work, we present MapLite: a one-click autonomous navigation system capable of piloting a vehicle to an arbitrary desired destination point given only a sparse publicly available topometric map (from OpenStreetMap). The onboard sensors are used to segment the road region and register the topometric map in order to fuse the high-level navigation goals with a variational path planner in the vehicle frame. This enables the system to plan trajectories that correctly navigate road intersections without the use of an external localization system such as GPS or a detailed prior map. Since the topometric maps already exist for the vast majority of roads, this solution greatly increases the geographical scope for autonomous mobility solutions. We implement MapLite on a full-scale autonomous vehicle and exhaustively test it on over 15km of road including over 100 autonomous intersection traversals. We further extend these results through simulated testing to validate the system on complex road junction topologies such as traffic circles.
@inproceedings{ ort2020maplite,
author = { Ort, Teddy and Murthy, Krishna and Banerjee, Rohan and Gottipati, Sai Krishna and Bhatt, Dhaivat and Gilitschenski, Igor and Paull, Liam and Rus, Daniela },
title = { MapLite: Autonomous Intersection Navigation without a Detailed Prior Map },
journal = { IEEE Robotics and Automation Letters },
year = { 2020 },
}
Integrated benchmarking and design for reproducible and accessible evaluation of robotic agents Jacopo Tani, Andrea F Daniele, Gianmarco Bernasconi, Amaury Camus, Aleksandar Petrov, Anthony Courchesne, Bhairav Mehta, Rohit Suri, Tomasz Zaluska, Matthew R Walter, and others In 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) 2020 Abstract arXiv BibTeX As robotics matures and increases in complexity, it is more necessary than ever that robot autonomy research be reproducible. Compared to other sciences, there are specific challenges to benchmarking autonomy, such as the complexity of the software stacks, the variability of the hardware and the reliance on data-driven techniques, amongst others. In this paper, we describe a new concept for reproducible robotics research that integrates development and benchmarking, so that reproducibility is obtained “by design” from the beginning of the research/development processes. We first provide the overall conceptual objectives to achieve this goal and then a concrete instance that we have built: the DUCKIENet. One of the central components of this setup is the Duckietown Autolab, a remotely accessible standardized setup that is itself also relatively low-cost and reproducible. When evaluating agents, careful definition of interfaces allows users to choose among local versus remote evaluation using simulation, logs, or remote automated hardware setups. We validate the system by analyzing the repeatability of experiments conducted using the infrastructure and show that there is low variance across different robot hardware and across different remote labs.
@inproceedings{ tani2020integrated,
author = { Tani, Jacopo and Daniele, Andrea F and Bernasconi, Gianmarco and Camus, Amaury and Petrov, Aleksandar and Courchesne, Anthony and Mehta, Bhairav and Suri, Rohit and Zaluska, Tomasz and Walter, Matthew R and others, },
title = { Integrated benchmarking and design for reproducible and accessible evaluation of robotic agents },
booktitle = { 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) },
year = { 2020 },
}
Perceptual generative autoencoders Zijun Zhang, Ruixiang Zhang, Zongpeng Li, Yoshua Bengio, and Liam Paull In International Conference on Machine Learning 2020 Abstract arXiv BibTeX Modern generative models are usually designed to match target distributions directly in the data space, where the intrinsic dimension of data can be much lower than the ambient dimension. We argue that this discrepancy may contribute to the difficulties in training generative models. We therefore propose to map both the generated and target distributions to a latent space using the encoder of a standard autoencoder, and train the generator (or decoder) to match the target distribution in the latent space. Specifically, we enforce the consistency in both the data space and the latent space with theoretically justified data and latent reconstruction losses. The resulting generative model, which we call a perceptual generative autoencoder (PGA), is then trained with a maximum likelihood or variational autoencoder (VAE) objective. With maximum likelihood, PGAs generalize the idea of reversible generative models to unrestricted neural network architectures and arbitrary number of latent dimensions. When combined with VAEs, PGAs substantially improve over the baseline VAEs in terms of sample quality. Compared to other autoencoder-based generative models using simple priors, PGAs achieve state-of-the-art FID scores on CIFAR-10 and CelebA.
@inproceedings{ zhang2020perceptual,
author = { Zhang, Zijun and Zhang, Ruixiang and Li, Zongpeng and Bengio, Yoshua and Paull, Liam },
title = { Perceptual generative autoencoders },
booktitle = { International Conference on Machine Learning },
year = { 2020 },
}
gradSim: Differentiable simulation for system identification and visuomotor control J Krishna Murthy, Miles Macklin, Florian Golemo, Vikram Voleti, Linda Petrini, Martin Weiss, Breandan Considine, Jérôme Parent-Lévesque, Kevin Xie, Kenny Erleben, and others In International Conference on Learning Representations 2020 Abstract arXiv Project Page BibTeX We consider the problem of estimating an object’s physical properties such as mass, friction, and elasticity directly from video sequences. Such a system identification problem is fundamentally ill-posed due to the loss of information during image formation. Current solutions require precise 3D labels which are labor-intensive to gather, and infeasible to create for many systems such as deformable solids or cloth. We present gradSim, a framework that overcomes the dependence on 3D supervision by leveraging differentiable multiphysics simulation and differentiable rendering to jointly model the evolution of scene dynamics and image formation. This novel combination enables backpropagation from pixels in a video sequence through to the underlying physical attributes that generated them. Moreover, our unified computation graph – spanning from the dynamics and through the rendering process – enables learning in challenging visuomotor control tasks, without relying on state-based (3D) supervision, while obtaining performance competitive to or better than techniques that rely on precise 3D labels.
@inproceedings{ murthy2020gradsim,
author = { Murthy, J Krishna and Macklin, Miles and Golemo, Florian and Voleti, Vikram and Petrini, Linda and Weiss, Martin and Considine, Breandan and Parent-Lévesque, Jérôme and Xie, Kevin and Erleben, Kenny and others, },
title = { gradSim: Differentiable simulation for system identification and visuomotor control },
booktitle = { International Conference on Learning Representations },
year = { 2020 },
}

A Data-Efficient Framework for Training and Sim-to-Real Transfer of Navigation Policies Homanga Bharadhwaj, Zihan Wang, Yoshua Bengio, and Liam Paull In IEEE International Conference on Robotics and Automation (ICRA) 2019 Abstract arXiv BibTeX Learning effective visuomotor policies for robots purely from data is challenging, but also appealing since a learning-based system should not require manual tuning or calibration. In the case of a robot operating in a real environment the training process can be costly, time-consuming, and even dangerous since failures are common at the start of training. For this reason, it is desirable to be able to leverage simulation and off-policy data to the extent possible to train the robot. In this work, we introduce a robust framework that plans in simulation and transfers well to the real environment. Our model incorporates a gradient-descent based planning module, which, given the initial image and goal image, encodes the images to a lower dimensional latent state and plans a trajectory to reach the goal. The model, consisting of the encoder and planner modules, is trained through a meta-learning strategy in simulation first. We subsequently perform adversarial domain transfer on the encoder by using a bank of unlabelled but random images from the simulation and real environments to enable the encoder to map images from the real and simulated environments to a similarly distributed latent representation. By fine tuning the entire model (encoder + planner) with far fewer real world expert demonstrations, we show successful planning performances in different navigation tasks.
@inproceedings{ bharadhwaj2018data,
author = { Bharadhwaj, Homanga and Wang, Zihan and Bengio, Yoshua and Paull, Liam },
title = { A Data-Efficient Framework for Training and Sim-to-Real Transfer of Navigation Policies },
booktitle = { IEEE International Conference on Robotics and Automation (ICRA) },
year = { 2019 },
}
Deep Active Localization Sai Krishna, Keehong Seo, Dhaivat Bhatt, Vincent Mai, Krishna Murthy, and Liam Paull In IEEE Robotics and Automation Letters (RAL) 2019 Abstract arXiv Code BibTeX Active localization is the problem of generating robot actions that allow it to maximally disambiguate its pose within a reference map. Traditional approaches to this use an information-theoretic criterion for action selection and hand-crafted perceptual models. In this work we propose an end-to-end differentiable method for learning to take informative actions that is trainable entirely in simulation and then transferable to real robot hardware with zero refinement. The system is composed of two modules: a convolutional neural network for perception, and a deep reinforcement learned planning module. We introduce a multi-scale approach to the learned perceptual model since the accuracy needed to perform action selection with reinforcement learning is much less than the accuracy needed for robot control. We demonstrate that the resulting system outperforms using the traditional approach for either perception or planning. We also demonstrate our approaches robustness to different map configurations and other nuisance parameters through the use of domain randomization in training. The code is also compatible with the OpenAI gym framework, as well as the Gazebo simulator.
@inproceedings{ sai2019dal,
author = { Krishna, Sai and Seo, Keehong and Bhatt, Dhaivat and Mai, Vincent and Murthy, Krishna and Paull, Liam },
title = { Deep Active Localization },
booktitle = { IEEE Robotics and Automation Letters (RAL) },
year = { 2019 },
}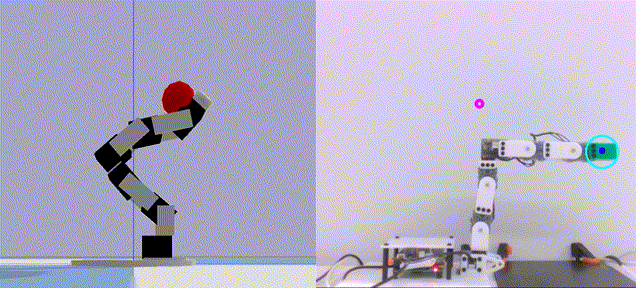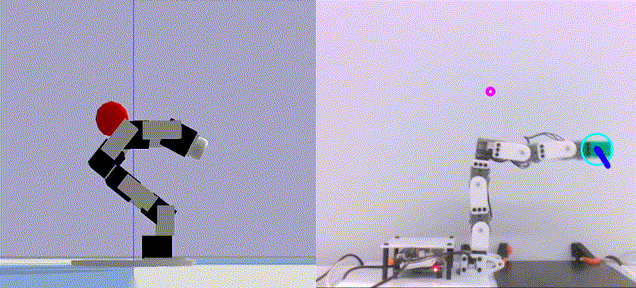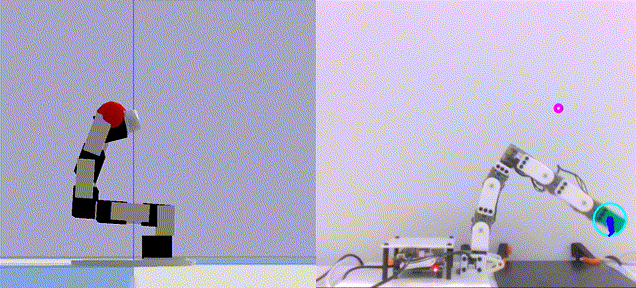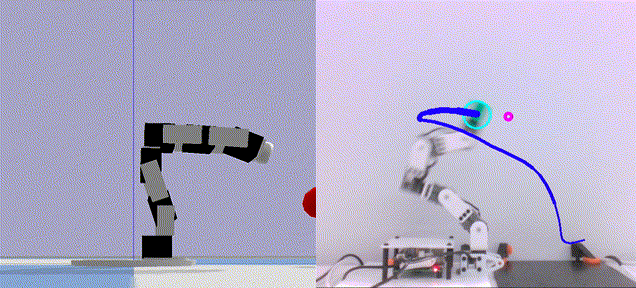
Active Domain Randomization Bhairav Mehta, Manfred Diaz, Florian Golemo, Christopher Pal, and Liam Paull In Conference on Robot Learning (CoRL) 2019 Abstract arXiv Code BibTeX We tackle the uniform sampling assumption in domain randomization and learn a randomization strategy, looking for the most informative environments. Our method shows significant improvements in agent performance, agent generalization, sample complexity, and interpretability over the traditional domain and dynamics randomization strategies.
@inproceedings{ adr,
author = { Mehta, Bhairav and Diaz, Manfred and Golemo, Florian and Pal, Christopher and Paull, Liam },
title = { Active Domain Randomization },
booktitle = { Conference on Robot Learning (CoRL) },
year = { 2019 },
}

Probabilistic cooperative mobile robot area coverage and its application to autonomous seabed mapping Liam Paull, Mae Seto, John J Leonard, and Howard Li In 2018 Abstract BibTeX There are many applications that require mobile robots to autonomously cover an entire area with a sensor or end effector. The vast majority of the literature on this subject is focused on addressing path planning for area coverage under the assumption that the robot’s pose is known or that error is bounded. In this work, we remove this assumption and develop a completely probabilistic representation of coverage. We show that coverage is guaranteed as long as the robot pose estimates are consistent, a much milder assumption than zero or bounded error. After formally connecting robot sensor uncertainty with area coverage, we propose an adaptive sliding window filter pose estimator that provides a close approximation to the full maximum a posteriori estimate with a computation cost that is bounded over time. Subsequently, an adaptive planning strategy is presented that automatically exploits conditions of low vehicle uncertainty to more efficiently cover an area. We further extend this approach to the multi-robot case where robots can communicate through a (possibly faulty and low-bandwidth) channel and make relative measurements of one another. In this case, area coverage is achieved more quickly since the uncertainty over the robots’ trajectories is reduced. We apply the framework to the scenario of mapping an area of seabed with an autonomous underwater vehicle. Experimental results support the claim that our method achieves guaranteed complete coverage notwithstanding poor navigational sensors and that resulting path lengths required to cover the entire area are shortest using the proposed cooperative and adaptive approach.
@inproceedings{ paull2018probabilistic,
author = { Paull, Liam and Seto, Mae and Leonard, John J and Li, Howard },
title = { Probabilistic cooperative mobile robot area coverage and its application to autonomous seabed mapping },
journal = { The International Journal of Robotics Research },
year = { 2018 },
}
Autonomous Vehicle Navigation in Rural Environments without Detailed Prior Maps Teddy Ort, Liam Paull, and Daniela Rus In IEEE International Conference on Robotics and Automation (ICRA) 2018 Abstract arXiv BibTeX State-of-the-art autonomous driving systems rely heavily on detailed and highly accurate prior maps. However, outside of small urban areas, it is very challenging to build, store, and transmit detailed maps since the spatial scales are so large. Furthermore, maintaining detailed maps of large rural areas can be impracticable due to the rapid rate at which these environments can change. This is a significant limitation for the widespread applicability of autonomous driving technology, which has the potential for an incredibly positive societal impact. In this paper, we address the problem of autonomous navigation in rural environments through a novel mapless driving framework that combines sparse topological maps for global navigation with a sensor-based perception system for local navigation. First, a local navigation goal within the sensor view of the vehicle is chosen as a waypoint leading towards the global goal. Next, the local perception system generates a feasible trajectory in the vehicle frame to reach the waypoint while abiding by the rules of the road for the segment being traversed. These trajectories are updated to remain in the local frame using the vehicle’s odometry and the associated uncertainty based on the least-squares residual and a recursive filtering approach, which allows the vehicle to navigate road networks reliably, and at high speed, without detailed prior maps. We demonstrate the performance of the system on a full-scale autonomous vehicle navigating in a challenging rural environment and benchmark the system on a large amount of collected data.
@inproceedings{ ort2018icra,
author = { Ort, Teddy and Paull, Liam and Rus, Daniela },
title = { Autonomous Vehicle Navigation in Rural Environments without Detailed Prior Maps },
booktitle = { IEEE International Conference on Robotics and Automation (ICRA) },
year = { 2018 },
}
Local Positioning System Using UWB Range Measurements for an Unmanned Blimp Vincent Mai, Mina Kamel, Matthias Krebs, Andreas Schaffner, Daniel Meier, Liam Paull, and Roland Siegwart In 2018 Abstract arXiv BibTeX Unmanned blimps are a safe and reliable alternative to conventional drones when flying above people. On-board real-time tracking of their pose and velocities is a necessary step toward autonomous navigation. There is a need for an easily deployable technology that is able to accurately and robustly estimate the pose and velocities of a blimp in 6 DOF, as well as unexpected applied forces and torques, in an uncontrolled environment. We present two multiplicative extended Kalman filters using ultrawideband radio sensors and a gyroscope to address this challenge. One filter is updated using a dynamics model of the blimp, whereas the other uses a constant speed model. We describe a set of experiments in which these estimators have been implemented on an embedded flight controller. They were tested and compared in accuracy and robustness in a hardware-in-loop simulation as well as on a real blimp. This approach can be generalized to any lighter than air robot to track it with the necessary accuracy, precision, and robustness to allow autonomous navigation.
@inproceedings{ mai2018local,
author = { Mai, Vincent and Kamel, Mina and Krebs, Matthias and Schaffner, Andreas and Meier, Daniel and Paull, Liam and Siegwart, Roland },
title = { Local Positioning System Using UWB Range Measurements for an Unmanned Blimp },
journal = { IEEE Robotics and Automation Letters },
year = { 2018 },
}
Geometric Consistency for Self-Supervised End-to-End Visual Odometry Ganesh Iyer, J Krishna Murthy, K Gunshi Gupta, and Liam Paull In CVPR Workshop on Deep Learning for Visual SLAM 2018 Abstract arXiv Project Page BibTeX With the success of deep learning based approaches in tackling challenging problems in computer vision, a wide range of deep architectures have recently been proposed for the task of visual odometry (VO) estimation. Most of these proposed solutions rely on supervision, which requires the acquisition of precise ground-truth camera pose information, collected using expensive motion capture systems or high-precision IMU/GPS sensor rigs. In this work, we propose an unsupervised paradigm for deep visual odometry learning. We show that using a noisy teacher, which could be a standard VO pipeline, and by designing a loss term that enforces geometric consistency of the trajectory, we can train accurate deep models for VO that do not require ground-truth labels. We leverage geometry as a self-supervisory signal and propose "Composite Transformation Constraints (CTCs)", that automatically generate supervisory signals for training and enforce geometric consistency in the VO estimate. We also present a method of characterizing the uncertainty in VO estimates thus obtained. To evaluate our VO pipeline, we present exhaustive ablation studies that demonstrate the efficacy of end-to-end, self-supervised methodologies to train deep models for monocular VO. We show that leveraging concepts from geometry and incorporating them into the training of a recurrent neural network results in performance competitive to supervised deep VO methods.
@inproceedings{ CTCNet,
author = { Iyer, Ganesh and Murthy, J Krishna and Gunshi Gupta, K and Paull, Liam },
title = { Geometric Consistency for Self-Supervised End-to-End Visual Odometry },
booktitle = { CVPR Workshop on Deep Learning for Visual SLAM },
year = { 2018 },
}
Learning steering bounds for parallel autonomous systems Alexander Amini, Liam Paull, Thomas Balch, Sertac Karaman, and Daniela Rus In IEEE International Conference on Robotics and Automation (ICRA) 2018 Abstract arXiv BibTeX Deep learning has been successfully applied to “end-to-end” learning of the autonomous driving task, where a deep neural network learns to predict steering control commands from camera data input. While these previous works support reactionary control, the representation learned is not usable for higher-level decision making required for autonomous navigation. This paper tackles the problem of learning a representation to predict a continuous control probability distribution, and thus steering control options and bounds for those options, which can be used for autonomous navigation. Each mode of the distribution encodes a possible macro-action that the system could execute at that instant, and the covariances of the modes place bounds on safe steering control values. Our approach has the added advantage of being trained on unlabeled data collected from inexpensive cameras. The deep neural network based algorithm generates a probability distribution over the space of steering angles, from which we leverage Variational Bayesian methods to extract a mixture model and compute the different possible actions in the environment. A bound, which the autonomous vehicle must respect in our parallel autonomy setting, is then computed for each of these actions. We evaluate our approach on a challenging dataset containing a wide variety of driving conditions, and show that our algorithm is capable of parameterizing Gaussian Mixture Models for possible actions, and extract steering bounds with a mean error of only 2 degrees. Additionally, we demonstrate our system working on a full scale autonomous vehicle and evaluate its ability to successful handle various different parallel autonomy situations.
@inproceedings{ amini2018learning,
author = { Amini, Alexander and Paull, Liam and Balch, Thomas and Karaman, Sertac and Rus, Daniela },
title = { Learning steering bounds for parallel autonomous systems },
booktitle = { IEEE International Conference on Robotics and Automation (ICRA) },
year = { 2018 },
}

Duckietown: an open, inexpensive and flexible platform for autonomy education and research Liam Paull, Jacopo Tani, Heejin Ahn, Javier Alonso-Mora, Luca Carlone, Michal Cap, Yu Fan Chen, Changhyun Choi, Jeff Dusek, Yajun Fang, and others In IEEE International Conference on Robotics and Automation (ICRA) 2017 Abstract arXiv BibTeX Duckietown is an open, inexpensive and flexible platform for autonomy education and research. The platform comprises small autonomous vehicles (“Duckiebots”) built from off-the-shelf components, and cities (“Duckietowns”) complete with roads, signage, traffic lights, obstacles, and citizens (duckies) in need of transportation. The Duckietown platform offers a wide range of functionalities at a low cost. Duckiebots sense the world with only one monocular camera and perform all processing onboard with a Raspberry Pi 2, yet are able to: follow lanes while avoiding obstacles, pedestrians (duckies) and other Duckiebots, localize within a global map, navigate a city, and coordinate with other Duckiebots to avoid collisions. Duckietown is a useful tool since educators and researchers can save money and time by not having to develop all of the necessary supporting infrastructure and capabilities. All materials are available as open source, and the hope is that others in the community will adopt the platform for education and research.
@inproceedings{ paull2017duckietown,
author = { Paull, Liam and Tani, Jacopo and Ahn, Heejin and Alonso-Mora, Javier and Carlone, Luca and Cap, Michal and Chen, Yu Fan and Choi, Changhyun and Dusek, Jeff and Fang, Yajun and others, },
title = { Duckietown: an open, inexpensive and flexible platform for autonomy education and research },
booktitle = { IEEE International Conference on Robotics and Automation (ICRA) },
year = { 2017 },
}
Hybrid control and learning with coresets for autonomous vehicles Guy Rosman, Liam Paull, and Daniela Rus In IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) 2017 Abstract arXiv BibTeX Modern autonomous systems such as driverless vehicles need to safely operate in a wide range of conditions. A potential solution is to employ a hybrid systems approach, where safety is guaranteed in each individual mode within the system. This offsets complexity and responsibility from the individual controllers onto the complexity of determining discrete mode transitions. In this work we propose an efficient framework based on recursive neural networks and coreset data summarization to learn the transitions between an arbitrary number of controller modes that can have arbitrary complexity. Our approach allows us to efficiently gather annotation data from the large-scale datasets that are required to train such hybrid nonlinear systems to be safe under all operating conditions, favoring underexplored parts of the data. We demonstrate the construction of the embedding, and efficient detection of switching points for autonomous and nonautonomous car data. We further show how our approach enables efficient sampling of training data, to further improve either our embedding or the controllers
@inproceedings{ rosman2017hybrid,
author = { Rosman, Guy and Paull, Liam and Rus, Daniela },
title = { Hybrid control and learning with coresets for autonomous vehicles },
booktitle = { IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) },
year = { 2017 },
}
Parallel autonomy in automated vehicles: Safe motion generation with minimal intervention Wilko Schwarting, Javier Alonso-Mora, Liam Paull, Sertac Karaman, and Daniela Rus In Robotics and Automation (ICRA), 2017 IEEE International Conference on 2017 Abstract PDF BibTeX Current state-of-the-art vehicle safety systems, such as assistive braking or automatic lane following, are still only able to help in relatively simple driving situations. We introduce a Parallel Autonomy shared-control framework that produces safe trajectories based on human inputs even in much more complex driving scenarios, such as those commonly encountered in an urban setting. We minimize the deviation from the human inputs while ensuring safety via a set of collision avoidance constraints. We develop a receding horizon planner formulated as a Non-linear Model Predictive Control (NMPC) including analytic descriptions of road boundaries, and the configurations and future uncertainties of other traffic participants, and directly supplying them to the optimizer without linearization. The NMPC operates over both steering and acceleration simultaneously. Furthermore, the proposed receding horizon planner also applies to fully autonomous vehicles. We validate the proposed approach through simulations in a wide variety of complex driving scenarios such as left-turns across traffic, passing on busy streets, and under dynamic constraints in sharp turns on a race track.
@inproceedings{ schwarting2017parallel,
author = { Schwarting, Wilko and Alonso-Mora, Javier and Paull, Liam and Karaman, Sertac and Rus, Daniela },
title = { Parallel autonomy in automated vehicles: Safe motion generation with minimal intervention },
booktitle = { Robotics and Automation (ICRA), 2017 IEEE International Conference on },
year = { 2017 },
}
A parallel autonomy research platform Felix Naser, David Dorhout, Stephen Proulx, Scott Drew Pendleton, Hans Andersen, Wilko Schwarting, Liam Paull, Javier Alonso-Mora, Marcelo H Ang, Sertac Karaman, and others In 2017 IEEE Intelligent Vehicles Symposium (IV) 2017 Abstract PDF BibTeX We present the development of a full-scale “parallel autonomy” research platform including software and hardware. In the parallel autonomy paradigm, the control of the vehicle is shared; the human is still in control of the vehicle, but the autonomy system is always running in the background to prevent accidents. Our holistic approach includes: (1) a drive-by-wire conversion method only based on reverse engineering mounting of relatively inexpensive sensors onto the vehicle implementation of a localization and mapping system, (4) obstacle detection and (5) a shared controller as well as (6) integration with an advanced autonomy simulation system (Drake) for rapid development and testing. The system can operate in three modes: (a) manual driving, (b) full autonomy, where the system is in complete control of the vehicle and (c) parallel autonomy, where the shared controller is implemented. We present results from extensive testing of a full-scale vehicle on closed tracks that demonstrate these capabilities.
@inproceedings{ naser2017parallel,
author = { Naser, Felix and Dorhout, David and Proulx, Stephen and Pendleton, Scott Drew and Andersen, Hans and Schwarting, Wilko and Paull, Liam and Alonso-Mora, Javier and Ang, Marcelo H and Karaman, Sertac and others, },
title = { A parallel autonomy research platform },
booktitle = { 2017 IEEE Intelligent Vehicles Symposium (IV) },
year = { 2017 },
}
Safe nonlinear trajectory generation for parallel autonomy with a dynamic vehicle model Wilko Schwarting, Javier Alonso-Mora, Liam Paull, Sertac Karaman, and Daniela Rus IEEE Transactions on Intelligent Transportation Systems 2017 PDF BibTeX @inproceedings{ schwarting2017safe,
author = { Schwarting, Wilko and Alonso-Mora, Javier and Paull, Liam and Karaman, Sertac and Rus, Daniela },
title = { Safe nonlinear trajectory generation for parallel autonomy with a dynamic vehicle model },
journal = { IEEE Transactions on Intelligent Transportation Systems },
year = { 2017 },
}

A Unified Resource-Constrained Framework for Graph SLAM Liam Paull, Guoquan Huang, and John J Leonard In IEEE International Conference on Robotics and Automation (ICRA) 2016 Abstract arXiv Poster Slides Code BibTeX Graphical methods have proven an extremely useful tool employed by the mobile robotics community to frame estimation problems. Incremental solvers are able to process incoming sensor data and produce maximum a posteriori (MAP) estimates in realtime by exploiting the natural sparsity within the graph for reasonable-sized problems. However, to enable truly longterm operation in prior unknown environments requires algorithms whose computation, memory, and bandwidth (in the case of distributed systems) requirements scale constantly with time and environment size. Some recent approaches have addressed this problem through a two-step process - first the variables selected for removal are marginalized which induces density, and then the result is sparsified to maintain computational efficiency. Previous literature generally addresses only one of these two components. In this work, we attempt to explicitly connect all of the aforementioned resource constraint requirements by considering the node removal and sparsification pipeline in its entirety. We formulate the node selection problem as a minimization problem over the penalty to be paid in the resulting sparsification. As a result, we produce node subset selection strategies that are optimal in terms of minimizing the impact, in terms of Kullback-Liebler divergence (KLD), of approximating the dense distribution by a sparse one. We then show that one instantiation of this problem yields a computationally tractable formulation. Finally, we evaluate the method on standard datasets and show that the KLD is minimized as compared to other commonly-used heuristic node selection techniques.
@inproceedings{ paull2016unified,
author = { Paull, Liam and Huang, Guoquan and Leonard, John J },
title = { A Unified Resource-Constrained Framework for Graph SLAM },
booktitle = { IEEE International Conference on Robotics and Automation (ICRA) },
year = { 2016 },
}
Slam with objects using a nonparametric pose graph Beipeng Mu, Shih-Yuan Liu, Liam Paull, John Leonard, and Jonathan P How In IEEE/RSJ International Conference onnIntelligent Robots and Systems (IROS) 2016 Abstract arXiv Video BibTeX Mapping and self-localization in unknown environments are fundamental capabilities in many robotic applications. These tasks typically involve the identification of objects as unique features or landmarks, which requires the objects both to be detected and then assigned a unique identifier that can be maintained when viewed from different perspectives and in different images. The data association and simultaneous localization and mapping (SLAM) problems are, individually, well-studied in the literature. But these two problems are inherently tightly coupled, and that has not been well-addressed. Without accurate SLAM, possible data associations are combinatorial and become intractable easily. Without accurate data association, the error of SLAM algorithms diverge easily. This paper proposes a novel nonparametric pose graph that models data association and SLAM in a single framework. An algorithm is further introduced to alternate between inferring data association and performing SLAM. Experimental results show that our approach has the new capability of associating object detections and localizing objects at the same time, leading to significantly better performance on both the data association and SLAM problems than achieved by considering only one and ignoring imperfections in the other.
@inproceedings{ mu2016iros,
author = { Mu, Beipeng and Liu, Shih-Yuan and Paull, Liam and Leonard, John and How, Jonathan P },
title = { Slam with objects using a nonparametric pose graph },
booktitle = { IEEE/RSJ International Conference onnIntelligent Robots and Systems (IROS) },
year = { 2016 },
}-
Slam with objects using a nonparametric pose graph Beipeng Mu, Shih-Yuan Liu, Liam Paull, John Leonard, and Jonathan P How In IEEE/RSJ International Conference onnIntelligent Robots and Systems (IROS) 2016 Abstract arXiv Video BibTeX Mapping and self-localization in unknown environments are fundamental capabilities in many robotic applications. These tasks typically involve the identification of objects as unique features or landmarks, which requires the objects both to be detected and then assigned a unique identifier that can be maintained when viewed from different perspectives and in different images. The data association and simultaneous localization and mapping (SLAM) problems are, individually, well-studied in the literature. But these two problems are inherently tightly coupled, and that has not been well-addressed. Without accurate SLAM, possible data associations are combinatorial and become intractable easily. Without accurate data association, the error of SLAM algorithms diverge easily. This paper proposes a novel nonparametric pose graph that models data association and SLAM in a single framework. An algorithm is further introduced to alternate between inferring data association and performing SLAM. Experimental results show that our approach has the new capability of associating object detections and localizing objects at the same time, leading to significantly better performance on both the data association and SLAM problems than achieved by considering only one and ignoring imperfections in the other.
@inproceedings{ mu2016irot,
author = { Mu, Beipeng and Liu, Shih-Yuan and Paull, Liam and Leonard, John and How, Jonathan P },
title = { Slam with objects using a nonparametric pose graph },
booktitle = { IEEE/RSJ International Conference onnIntelligent Robots and Systems (IROS) },
year = { 2016 },
}
 |
|
 |
|
